
|
Second-year Ph.D. StudentDepartment of Computer Science, The University of Hong Kong
|
About Me [back top]
I am currently a second-year Ph.D. student in the University of Hong Kong, fortunately supervised by Prof. Ping Luo at the MMLAB@HKU. Earlier, I received the master and bachelor degree from MAC@XMU, Xiamen University, and advised by Prof. Rongrong Ji.
My research interests are to develop efficient models, including both vision and language models. Recently, I focus on develop efficient training and inference algorithm for Large Language Models (LLMs).
I am actively looking for academic collaboration, fell free to contact me if you are interested.
Latest News [back top]
- [2026.05]: QAT Scaling Law and INT vs. FP are accepted by ICML, and INT vs. FP is selected as Spotlight paper.
- [2025.11]: Awarded the Bytedance Scholarship
(20W RMB, 20 students in China and Singapore) - [2025.05]: EfficientQAT is accepted by ACL Main.
- [2024.10]: Awarded the 中国电子学会-腾讯博士生科研激励计划
(10W RMB, 17 PHD students in China) - [2024.09] Start the PHD journal at HKU-MMLab
- [2024.01]: Two paper are accepted by ICLR 2024, including one Spotlight
- [2023.10]: Awarded the National Scholarship (国家奖学金)
- [2023.07]: Two paper are accepted by ICCV 2023
- [2023.07]: One paper is accepted by IJCV
- [2022.11]: One paper is accepted as oral presentation by AAAI 2023
Selected Publications [back top]
Preprint
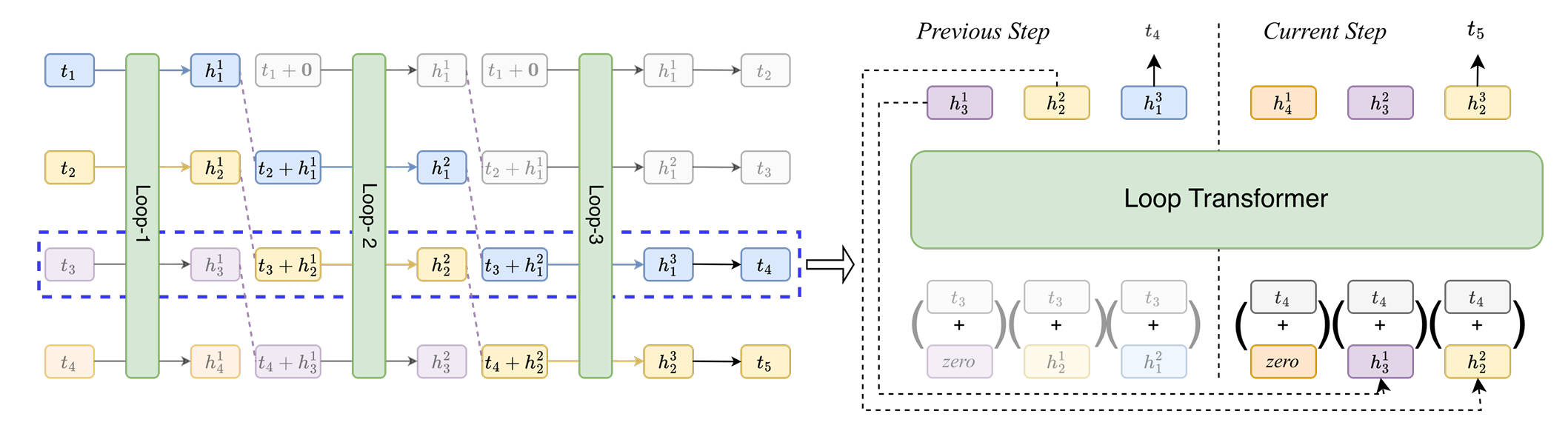 |
Bohong Wu*, Mengzhao Chen*, Xiang Luo, Shen Yan, Qifan Yu, Fan Xia, Tianqi Zhang, Hongrui Zhan, Zheng Zhong, Xun Zhou, Siyuan Qiao, Xingyan Bin✉
Parallel Loop Transformer for Efficient Test-Time Computation Scaling [arXiv] (* Equal Contribution) |
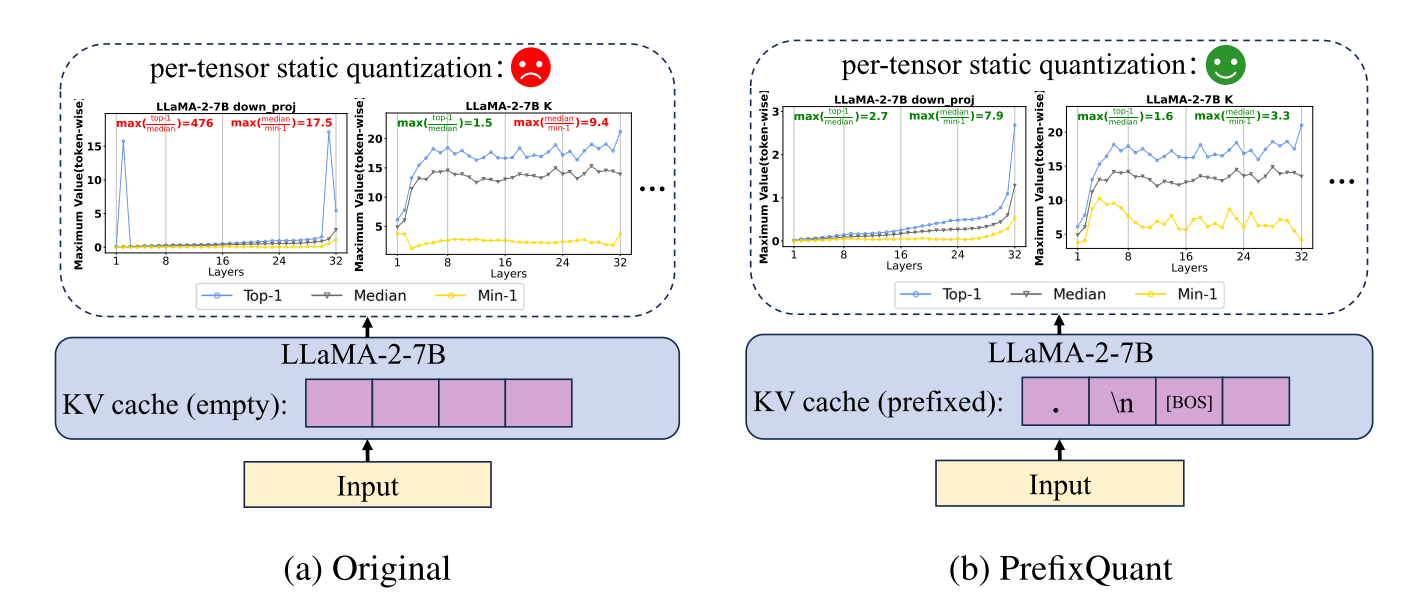 |
Mengzhao Chen, Yi Liu, Jiahao Wang, Yi Bin, Wenqi Shao✉, Ping Luo✉
PrefixQuant: Eliminating Outliers by Prefixed Tokens for Large Language Models Quantization [arXiv] [code  ] ]
|
Publications
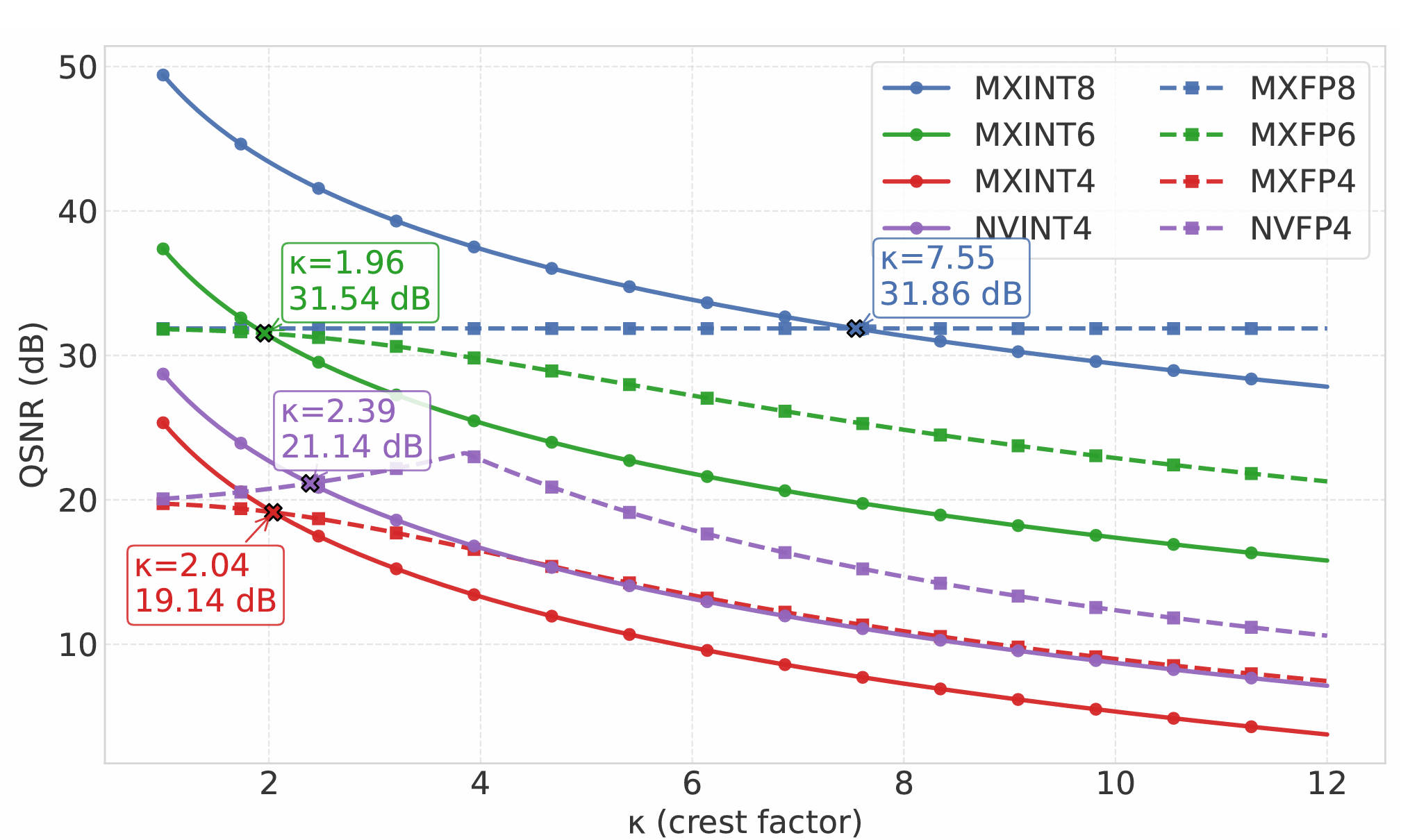 |
Mengzhao Chen, Meng Wu, Hui Jin, Zhihang Yuan, Jing Liu, Chaoyi Zhang, Yunshui Li, Jie Huang, Jin Ma, Zeyue Xue, Zhiheng Liu, Xingyan Bin✉, Ping Luo✉
INT vs. FP: A Comprehensive Study of Fine-Grained Low-bit Quantization Formats International Conference on Machine Learning (ICML), 2026 [arXiv] [code  ] ]
|
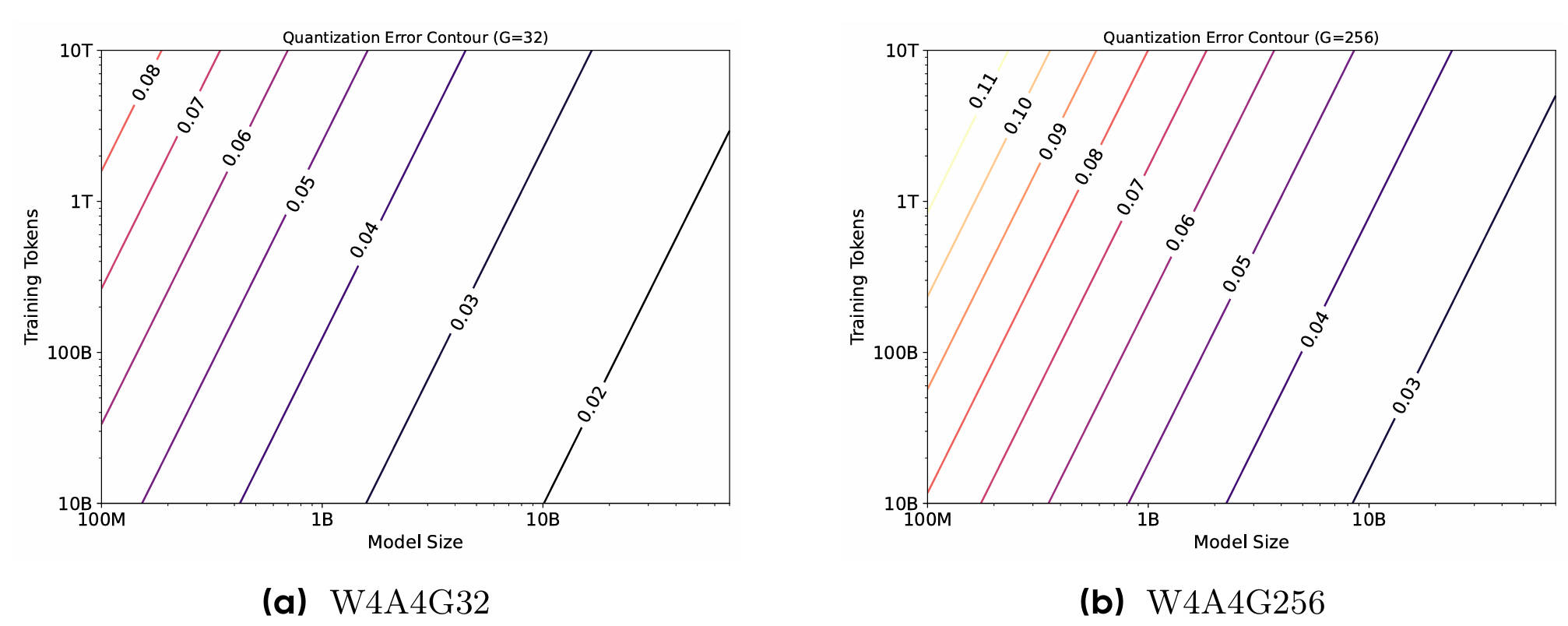 |
Mengzhao Chen, Chaoyi Zhang, Jing Liu, Yutao Zeng, Zeyue Xue, Zhiheng Liu, Yunshui Li, Jin Ma, Jie Huang, Xun Zhou✉, Ping Luo✉
Scaling Law for Quantization-Aware Training International Conference on Machine Learning (ICML, Spotlight), 2026 [arXiv] |
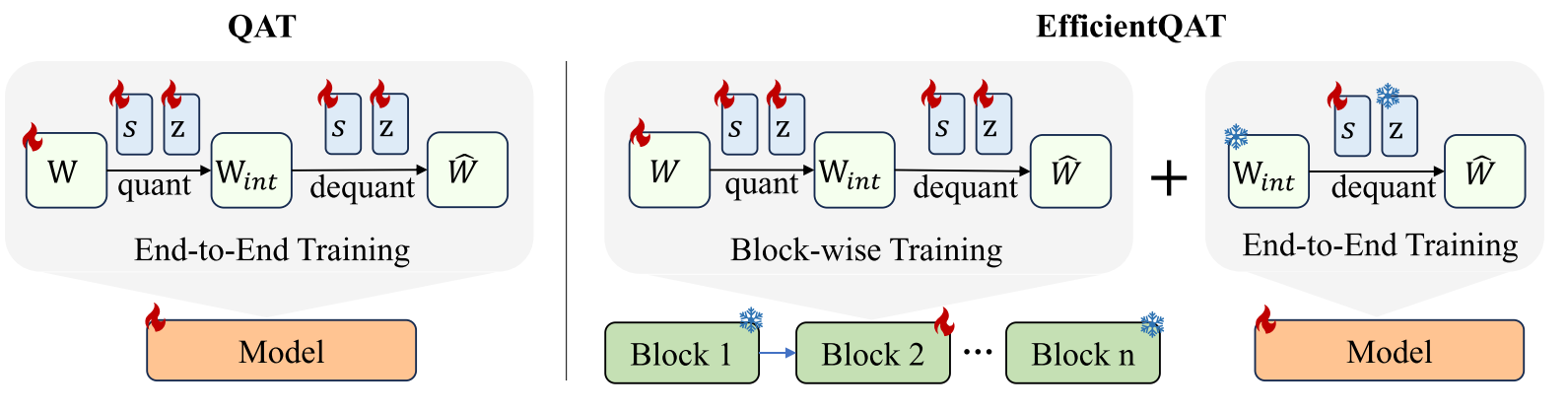 |
Mengzhao Chen, Wenqi Shao✉, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, Yu Qiao, Ping Luo✉
EfficientQAT: Efficient Quantization-Aware Training for Large Language Models Association for Computational Linguistics (ACL, Main), 2025 [arXiv] [code  ]
[中文介绍] ]
[中文介绍]
|
 |
Wenqi Shao*,Mengzhao Chen*, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo✉
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models International Conference on Learning Representations (ICLR, Spotlight), 2024 [arXiv] [code  ]
[中文介绍]
(* Equal Contribution) ]
[中文介绍]
(* Equal Contribution)
|
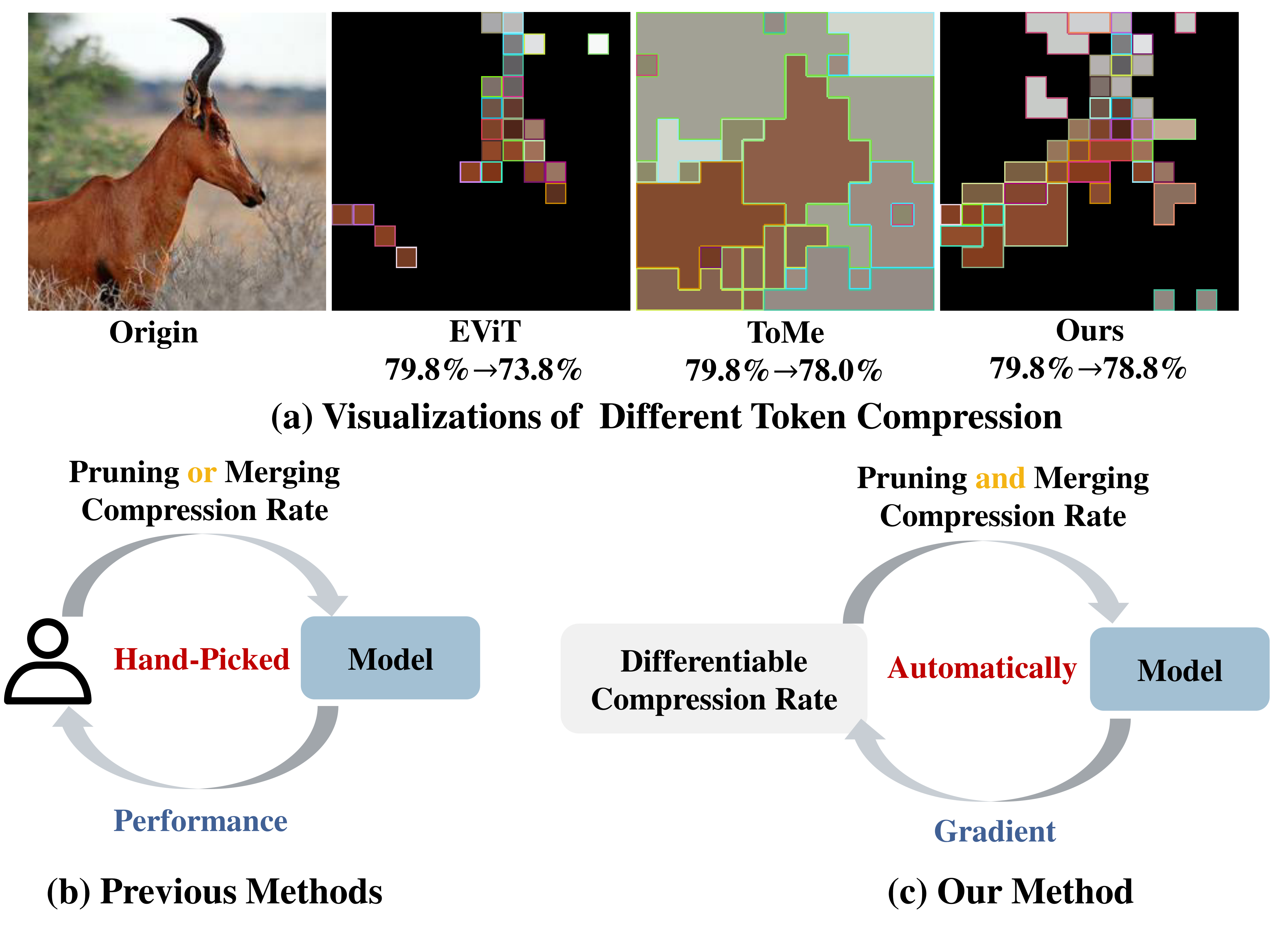 |
Mengzhao Chen,Wenqi Shao✉, Peng Xu, Mingbao Lin, Kaipeng Zhang, Fei Chao, Rongrong Ji✉, Yu Qiao, Ping Luo
DiffRate : Differentiable Compression Rate for Efficient Vision Transformers International Conference on Computer Vision (ICCV), 2023 [arXiv] [code  ]
[中文介绍]
[直播回放] ]
[中文介绍]
[直播回放]
|
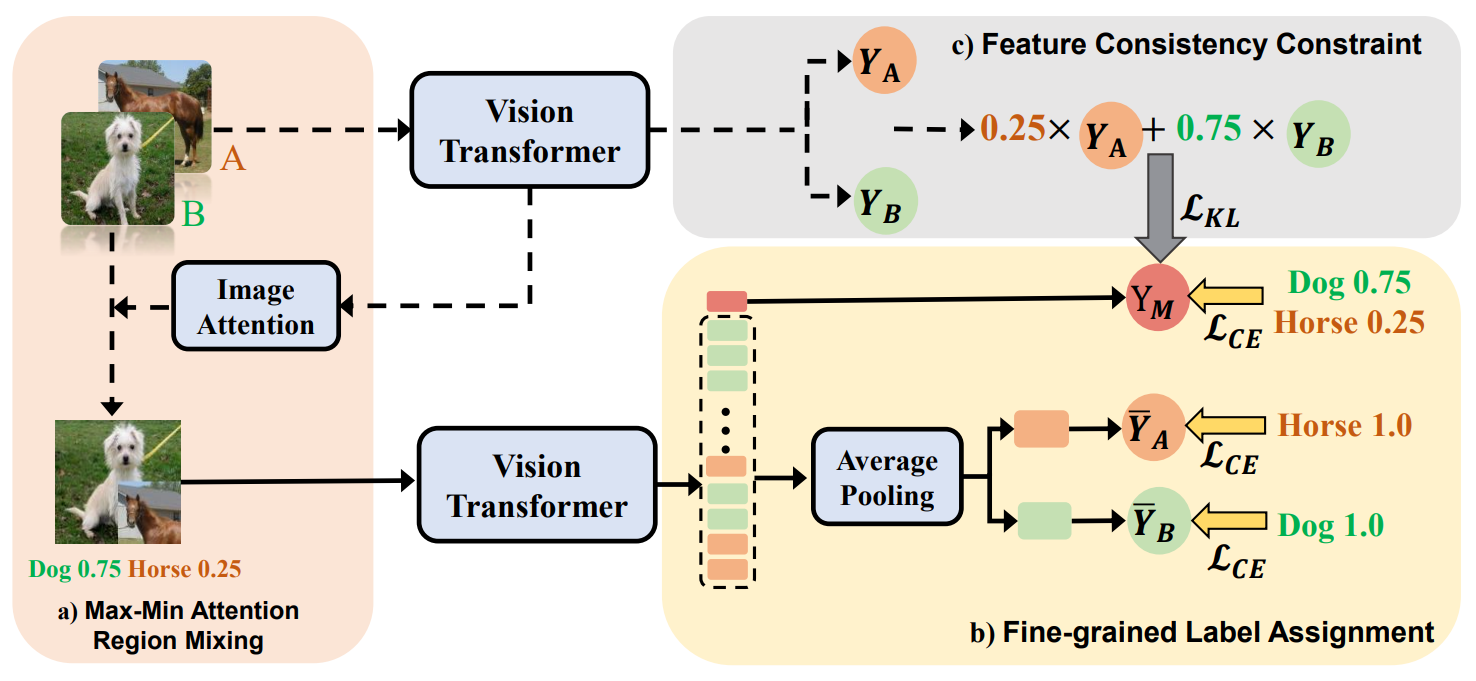 |
Mengzhao Chen, Mingbao Lin, Zhihang Lin, Yuxin Zhang, Fei Chao, Rongrong
Ji✉
SMMix: Self-Motivated Image Mixing for Vision Transformers International Conference on Computer Vision (ICCV), 2023 [arXiv] [code] |
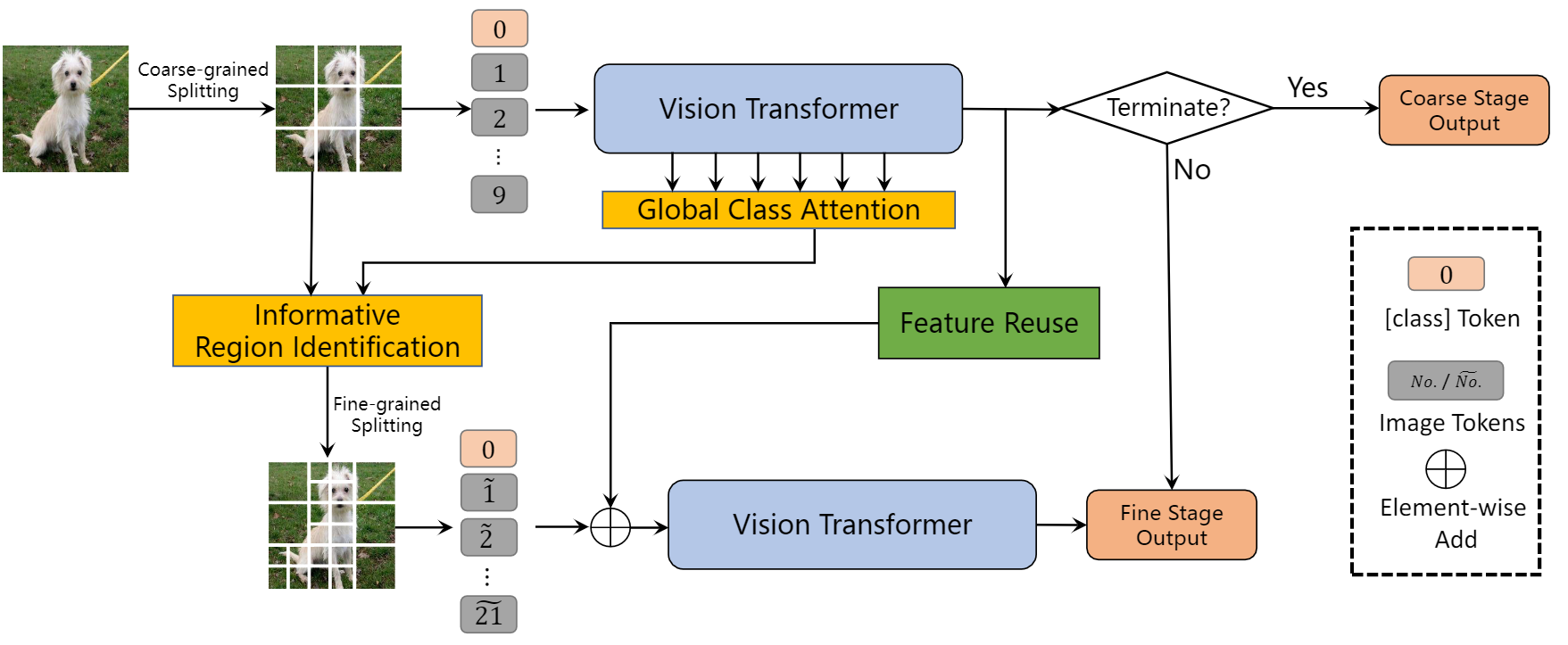 |
Mengzhao Chen, Mingbao Lin, Ke Li, Yunhang Shen, Yongjian Wu, Fei Chao, Rongrong
Ji✉
CF-ViT: A General Coarse-to-Fine Method for Vision Transformer AAAI Conference on Artificial Intelligence (AAAI, Oral), 2023 [arXiv] [code  ]
[中文介绍] ]
[中文介绍]
|
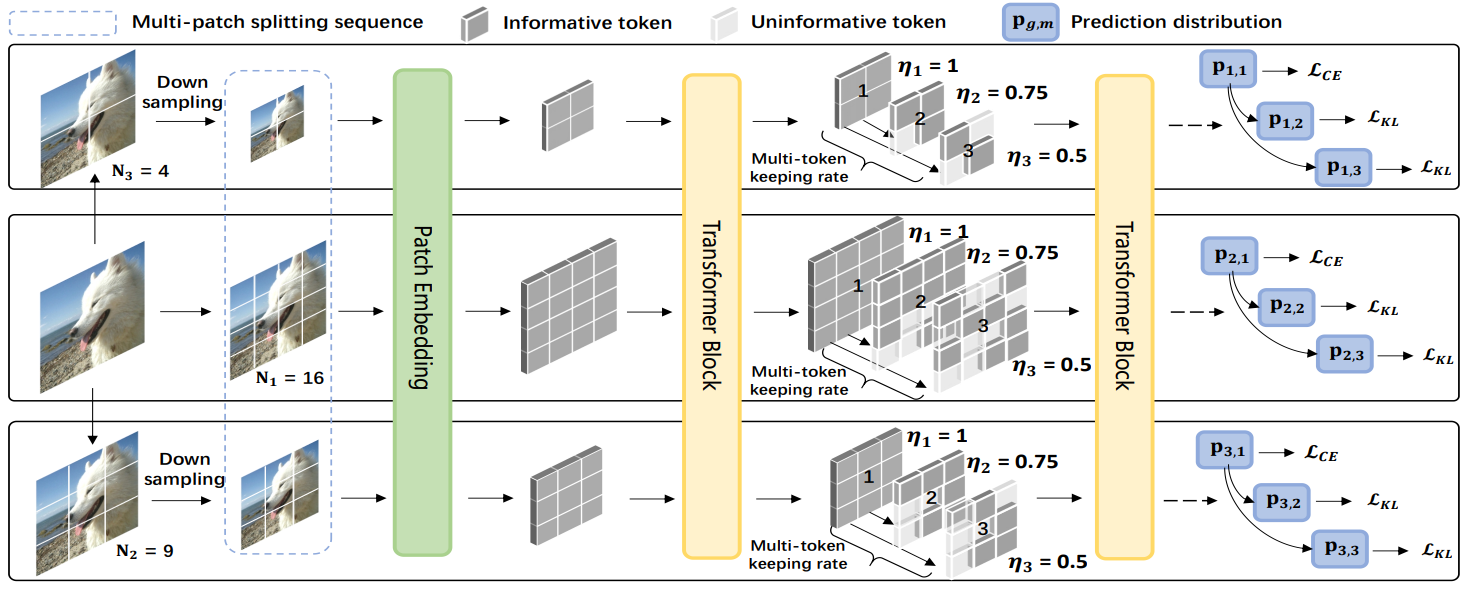 |
Mingbao Lin*, Mengzhao Chen*, Yuxin Zhang, Ke Li, Yunhang
Shen, Chunhua Shen,
Rongrong Ji, Liujuan Cao✉
Super Vision Transformer International Journal of Computer Vision (IJCV), 2023 [arXiv] [code] (* Equal Contribution) |
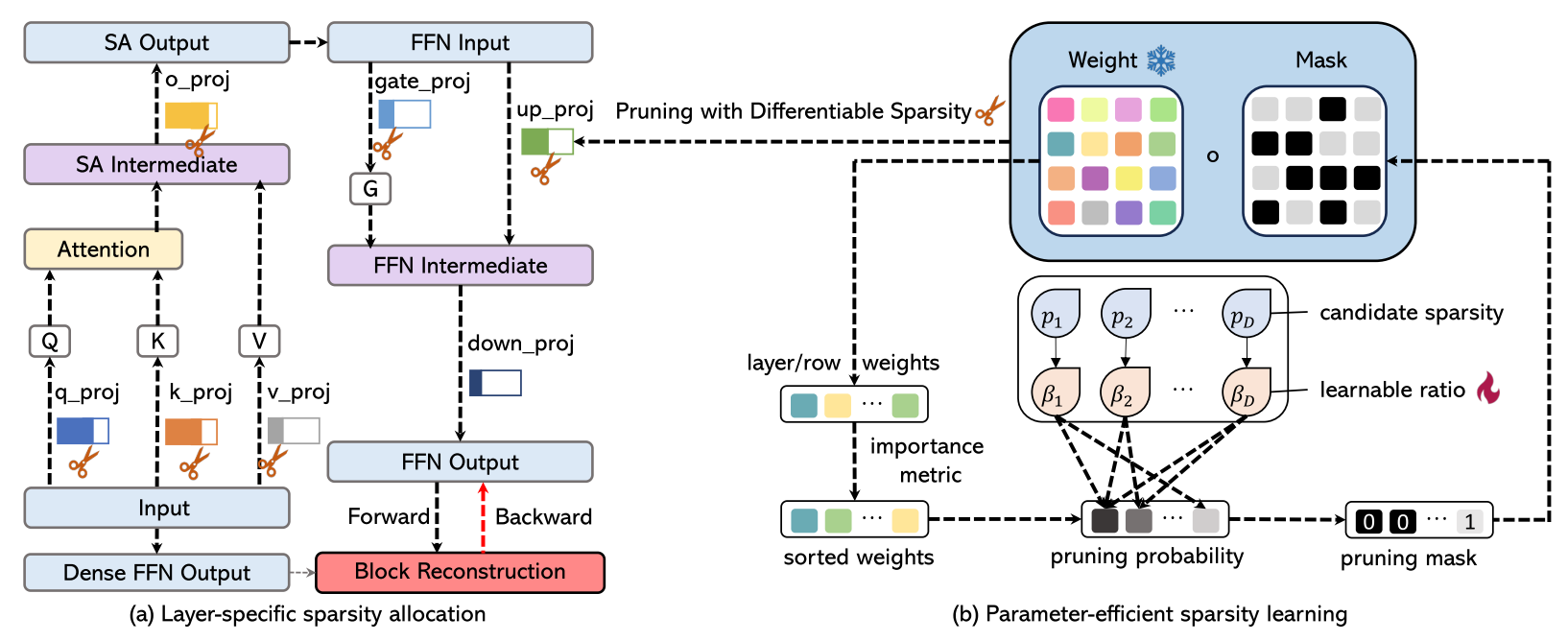 |
Peng Xu, Wenqi Shao✉,Mengzhao Chen, Shitong Tang, Kaipeng Zhang, Peng Gao, Fengwei An, Yu Qiao, Ping Luo✉
Besa: Pruning large language models with blockwise parameter-efficient sparsity allocation International Conference on Learning Representations (ICLR), 2024 [arXiv] [code] |
Major Awards [back top]
- Bytedance Scholarship, 2025
(20W RMB, 20 students in China and Singapore) - 中国电子学会-腾讯博士生科研激励计划, 2024
(10W RMB, 17 PHD students in China) - Outstanding Graduate Student, Xiamen University, 2024
- National Scholarship (国家奖学金), Ministry of Education of China, 2023
- Outstanding Graduate Student, Xiamen University, 2021
Academic Service [back top]
- Reviewer of TPAMI, IJCV, TMLR
- Reviewer of NeruIPS, ICLR, ICML, CVPR, ECCV, ICCV, CPAL, AISTATS